Eind september verliep het patent op een van de belangrijkste algoritmes voor de belangrijkste zoekmachine: Google PageRank. Hoe werkt dat algoritme precies?
Google PageRank doet precies wat de naam suggereert: pagina’s in Google rangschikken. Al is het ook een verwijzing naar Larry Page, die samen met Sergey Brin Google oprichtte.
Toen ze in 1998 Google boven de doopvont hielden, hadden Brin en Page op zich niets nieuws gedaan. Er waren immers al zoekmachines die zoekresultaten konden rangschikken op ‘beste overeenkomst met de zoekopdracht’. Maar hun PageRank-algoritme was wel anders dan de rest. Tot dan toe maakten algoritmes enkel gebruik van de tekstuele inhoud die ze vonden op pagina’s. Dat zette de deur open voor manipulatie. Websitebouwers konden bijvoorbeeld populaire maar binnen de context compleet irrelevante termen op hun sitepagina’s zetten en die onzichtbaar maken. De lezer had er geen last van, en de pagina’s verschenen in de zoekresultaten voor die termen. Ze kwamen onterecht hoger in de rangschikking.
Hoe meer links (en shares op social media) naar een pagina, hoe groter de kans dat de willekeurig klikkende surfer op die pagina terechtkomt
Het lumineuze idee van Brin en Page bestond erin dat ze de tekst op een pagina koppelden aan een ‘score van belang’ van een pagina. De twee haalden de mosterd voor het idee bij de onderzoekswereld. Als doctoraatsstudenten aan de Stanford University waren ze bekend met de zogenaamde citatie-index. Die berekent een score van belang voor auteurs van wetenschappelijke publicaties door te kijken naar hoe vaak hun publicaties worden geciteerd. Hoe meer citaties, hoe belangrijker de auteur (of toch zijn of haar werk). Brin en Page vertaalden citaties simpelweg naar links. Hoe meer links een pagina ontvangt, hoe belangrijker ze is.
Om dat verder uit te werken, vertrokken ze van een denkbeeldig persoon, die surft door telkens willekeurig een link aan te klikken op een pagina. Elke pagina krijgt dan een kans om te worden bereikt door de surfer. Hoe meer links (en shares op social media) naar een pagina, hoe groter de kans dat de willekeurig klikkende surfer op die pagina terechtkomt. En dus: hoe groter de PageRank-score voor die pagina.
Wiskundig kan je dat allemaal modelleren met een ‘willekeurige wandeling’ op een zogenaamde graaf. Die weerspiegelt de verzameling van alle webpagina’s en hoe ze onderling gelinkt zijn. Je kan dan een matrix opstellen die alle pagina’s tegen elkaar uitzet. Hierbij hou je rekening met hoeveel links er op de verwijzende pagina staan, samen met de score van die pagina. Een pagina met een hoge score geeft op die manier een deel van haar ‘belang’ door.
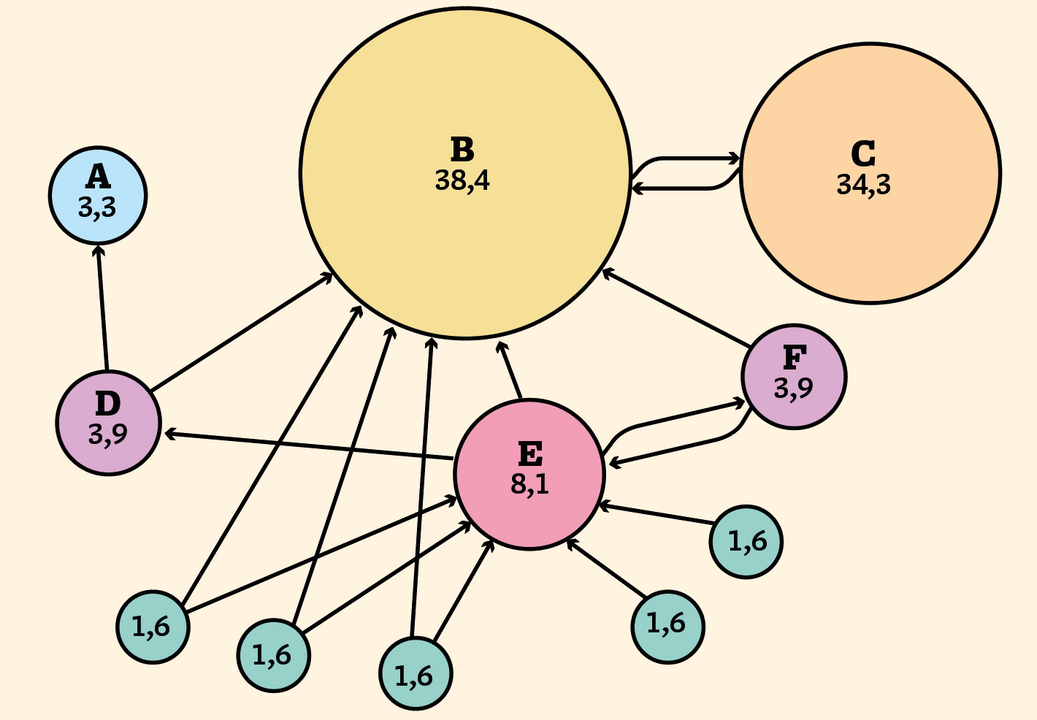
De uiteindelijke PageRank van een pagina kan je via eenvoudige lineaire-algebratechnieken bepalen. In de bovenstaande zien we een graaf die een aantal gelinkte pagina’s voorstelt. De cijfers zijn de PageRank-scores, die aangeven welke kans de pagina heeft dat ze wordt bezocht. Pagina C ontvangt maar één link, terwijl pagina E er vijf ontvangt. Toch krijgt pagina C van het algoritme een hogere PageRank, omdat de ene link die ze ontvangt komt van pagina B – een pagina met een hoge PageRank.
Wat als de surfer terechtkomt op een pagina zonder links? Brin en Page gingen ervan uit dat hij dan – opnieuw willekeurig – een pagina kiest om van daaruit verder te klikken en surfen. Hun idee is dat surfers die op een willekeurige pagina starten in 85 procent van de gevallen een willekeurige link vanop diezelfde pagina kiezen. In de andere 15 procent van de gevallen kiest de surfer geen link van die pagina, maar van een andere pagina, op een andere, willekeurige website. Als een surfer op een linkloze pagina belandt, komt die dus in dat laatste scenario terecht.
Zonder deze veronderstelling zouden al deze surfers uiteindelijk terechtkomen op de pagina’s A, B of C, waardoor alle andere pagina’s een PageRank nul zouden krijgen.
Aan de techniek zijn enkele nadelen verbonden. De graaf moet bijvoorbeeld regelmatig worden onderhouden, om de structuur en de bijbehorende paginascores up to date te houden. Verder worden oudere pagina’s bevoordeeld. Surfers worden ook dikwijls gelokt met clickbait, al heeft Google dat in 2016 al min of meer kunnen verhelpen.
Hoe het huidige algoritme precies werkt, is geheim. Google zegt dat het dat zo wil houden, om misbruik tegen gaan. Anderzijds zijn wij natuurlijk nooit zeker dat ons vertrouwen in de zoekresultaten niet wordt misbruikt door Google.



