
Artificiële intelligentie steunt op het verwerken van grote hoeveelheden data en dat kost veel energie. Een nieuwe chip, waarbij deze berekeningen door middel van analoge technologie rechtstreeks in het geheugen worden uitgevoerd, kan dat energieverbruik drastisch reduceren.
Onze planeet warmt op. Om dat probleem aan te pakken, is een klimaattransitie nodig. Die transitie vormt de drijvende kracht achter het werkprogramma van de Europese Commissie voor 2020, getiteld ‘naar een eerlijk, klimaatneutraal en digitaal Europa’.
Naast een ecologische transitie staan we tegelijk ook voor een digitale transitie. De digitale transformatie is dan ook het tweede speerpunt in het EU-programma, met een bijzondere nadruk op artificiële intelligentie (AI). Wanneer de Europese Commissie stelt dat “technologieën zoals AI een cruciale factor zullen vormen om de doelstellingen van de Green Deal te bereiken”, koppelt ze beide speerpunten aan elkaar. Het idee erachter: AI inzetten als wapen in de strijd tegen klimaatopwarming.
De ecologische kost van AI
Artificiële intelligentie heeft veel potentieel om bijvoorbeeld meer accurate klimaatvoorspellingen te maken, om energieverlies op te sporen of om verschillende industrieën te helpen decarboniseren. Daar staat tegenover dat de technologie zélf ook met een ecologische kost komt. Ze steunt immers op het verwerken van gigantische hoeveelheden data. Dat vraagt nu al een substantieel deel van de wereldwijde elektriciteitsproductie. Bovendien neemt het aantal berekeningen exponentieel toe. Hoewel die berekeningen typisch uitgevoerd worden in datacenters die de voorbije jaren al veel energie-efficiënter zijn geworden en deels gebruik maken van hernieuwbare energie, is de impact op onze planeet aanzienlijk.
Onderzoekers van de universiteit van Massachusetts rekenden vorig jaar bijvoorbeeld de emissie uit die gepaard gaat met het trainen van modellen in natural language processing (voornamelijk gebruikt om vertaalmachines te verbeteren). Dat deden ze door verschillende algoritmes kort te testen op één grafische processor, het stroomverbruik te extrapoleren met de gerapporteerde trainingsduur en dat om te zetten naar de CO2-uitstoot op basis van de gemiddelde energiemix bij verschillende cloudproviders. Conclusie: bij het finetunen van het meest energieverslindende algoritme komt tot 284 ton CO2 vrij. Dat is equivalent aan de CO2-emissie van vijf auto’s tijdens hun totale levensduur, inclusief de bouw ervan.
Er ontstaat dan ook een groeiend bewustzijn bij AI-onderzoekers om meer rekening te houden met de ecologische kost van de algoritmes die ze aan het ontwikkelen zijn. Sinds kort kunnen onderzoekers hun totale rekentijd en de daarvoor gebruikte hardware en clouddienst invoeren in een Machine Learning Emissions Calculator, waarna de geschatte CO2-uitstoot wordt opgenomen in hun paper.
Naar groene AI-hardware
In essentie kan je die ecologische voetafdruk op twee verschillende manieren beperken: via de software en via de hardware. Je kan efficiëntere algoritmes proberen ontwikkelen waarbij het aantal berekeningen geminimaliseerd wordt. Een typisch voorbeeld is de techniek van network pruning. Daarbij ‘snoei’ je alle onderdelen weg die weinig belang hebben voor het eindresultaat. Wat dan overblijft is een neuraal netwerk dat dezelfde functionaliteit heeft, maar kleiner, sneller en energie-efficiënter is.
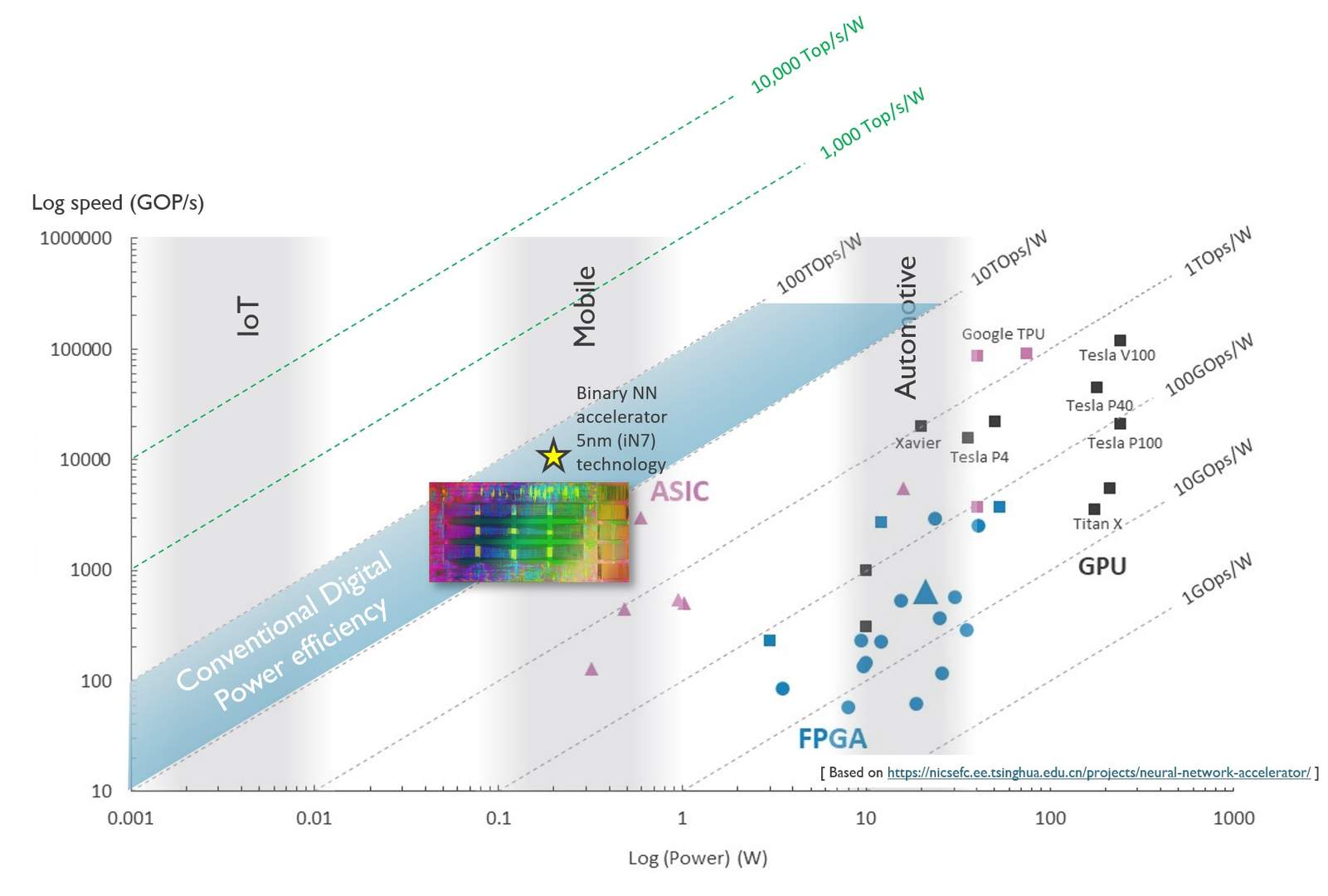
Daarnaast kan je ook energiezuinige hardware ontwerpen. Op dit moment worden AI-berekeningen vooral uitgevoerd op grafische processoren (GPU’s). Die processoren zijn niet speciaal voor dit soort berekeningen ontworpen, maar hun architectuur bleek er wel goed voor geschikt. Door de brede beschikbaarheid van GPU’s namen neurale netwerken een hoge vlucht. De voorbije jaren werden ook processoren ontwikkeld om specifiek AI-berekeningen te versnellen (zoals de Tensor Processing Units - TPU’s - van Google). Deze processoren kunnen meer berekeningen per seconde uitvoeren dan GPU’s, terwijl ze evenveel energie verbruiken. Andere systemen doen dan weer beroep op zogenaamde FPGA’s, die minder energie verbruiken maar ook veel minder snel rekenen. Vergelijk je de verhouding tussen rekensnelheid en energieverbruik, dan scoort de ASIC, een concurrent van de FPGA, het best. In onderstaande figuur worden de snelheid en het energieverbruik van verschillende componenten met elkaar vergeleken. De verhouding tussen beide, de energieprestatie, wordt uitgedrukt in TOPS/W (tera operations per second per Watt of het aantal biljoen berekeningen dat je per energie-eenheid kan uitvoeren). Om die energie-efficiëntie drastisch naar omhoog te krijgen, van 1 TOPS/W richting 10 000 TOPS/W, is echter volledig nieuwe technologie nodig.
Van de cloud naar de edge
Momenteel worden de meeste berekeningen naar de processoren van een datacenter gestuurd. We kunnen er echter ook voor kiezen om (een deel van) de AI-berekeningen op een andere plaats te gaan uitvoeren. “Je kan veel energie besparen als je erin slaagt om de data lokaal te verwerken”, vertelt Diederik Verkest, programma-directeur machine learning bij imec. “Het opgetelde energieverbruik van alle datacenters in de wereld is gigantisch, maar de hoeveelheid energie om data van je toestel naar de datacenters te sturen is ongeveer even groot. Die transmissie-energie wordt vermeden als de berekeningen in het toestel zélf zouden worden uitgevoerd.”
Daarbij kunnen we inspelen op een evolutie die al volop gaande is: die van de cloud naar de ‘edge’. Via steeds kleiner wordende apparaten worden steeds meer gegevens verzameld. Willen we die data ook rechtstreeks op het ‘edge device’ kunnen verwerken, dan moet het energieverbruik voor die berekeningen sowieso sterk naar omlaag. Hoe laag? “Dat hangt af van de grootte van het toestel waarin ze uitgevoerd worden”, legt Verkest uit. Het concept ‘edge device’ kan namelijk op verschillende manieren ingevuld worden. Het kan gaan over een kleine IoT-sensor of over een mobiele telefoon, maar evengoed over een zelfrijdende auto. “In een zelfrijdende auto zijn snelle beslissingen van levensbelang en heb je niet de tijd om de berekeningen heen en weer naar een datacenter te sturen. Dus wordt de koffer momenteel volgepropt met GPU’s die de beelden lokaal verwerken”, vertelt Verkest.
“In het geval van beeldherkenning spreek je over twintig biljoen operaties om één object te classificeren. In een datacenter zou je die berekeningen in een fractie van een seconde uitvoeren met GPU’s die zo’n 200 Watt verbruiken. Ben je al tevreden met rekentijd van één seconde om één beeld te herkennen, dan volstaat een GPU van 20 Watt. Dat kan nog haalbaar zijn in een auto, maar voor kleinere toestellen is dat energieverbruik te hoog. Als de batterij van je smartphone een capaciteit van 4000 mAh heeft, dan heb je 14.8 Wh ter beschikking. Mochten we daarin een GPU van 20 Watt laten draaien, dan zou je je smartphone na minder dan drie kwartier plat al opnieuw moeten opladen. Voor IoT-sensoren, waar de batterij nog veel langer moet meegaan, wordt het gebruik van dit soort processoren al helemaal onhaalbaar. Voor dat segment bestaan vandaag zelfs nog geen oplossingen”, zegt Verkest. “Daarom bewandelen we nu volledig nieuwe paden.”
Traditionele computerarchitectuur op de schop
Om draadloze toestellen snel beslissingen te laten nemen, moet dus nieuwe computerarchitectuur ontworpen worden. Meer specifiek is er een energiezuinige oplossing nodig voor de fase waarin voorspellingen gemaakt worden. Vooraleer een algoritme voorspellingen kan maken, moet het eerst ‘getraind’ worden. De berekeningen tijdens deze leerfase kunnen evengoed op voorhand in het datacenter uitgevoerd worden. Eens de leerfase achter de rug is, moet het slimme toestel zelf nieuwe data kunnen verwerken om de juiste voorspelling te kunnen maken. Het is dit deel van de berekeningen, de zogenaamde ‘inferentie’, die lokaal zal uitgevoerd worden.
Stel bijvoorbeeld dat we een AI-systeem geleerd hebben om een kat van een hond te onderscheiden. Dat betekent dat we een neuraal netwerk heel veel dierenfoto’s hebben voorgeschoteld en we het voortdurend feedback hebben gegeven tot het zijn paramaters zodanig heeft geoptimaliseerd dat het de juiste voorspelling kan maken. Tonen we nu een nieuwe dierenfoto, dan kan het algoritme op eigen houtje tot een waardevolle output komen (bijvoorbeeld ‘dit is met 95 procent waarschijnlijkheid een kat’). Tijdens deze inferentiefase moet het systeem grote hoeveelheden data doorploegen. Daarbij worden niet alleen de nieuwe kattenfoto, maar ook de eerder aangeleerde parameters opgehaald uit het geheugen. Het verplaatsen van die data vraagt veel energie.
Sinds de begindagen van het digitale computertijdperk is de processor gescheiden van het geheugen. In de processor worden bewerkingen uitgevoerd op data-elementjes die uit het geheugen worden opgehaald. Als die bewerkingen uitgevoerd worden op gigantische hoeveelheden data, duurt het ophalen ervan soms langer dan de tijd die nodig is om de bewerking uit te voeren. Dit probleem komt vooral tot uiting bij AI-berekeningen, omdat de inferentiefase afhankelijk is van het vermenigvuldigen van grote vectoren en matrices.
Bovendien wordt elke bewerking uitgevoerd met de precisie van een digitale computer, wat ook nog eens veel energie vraagt. De voorbije jaren hebben onderzoekers nochtans vastgesteld dat het eindresultaat (de patroonherkenning) amper beïnvloed wordt door de rekenprecisie waarmee iedere individuele bewerking wordt uitgevoerd. Je zou dus energie kunnen besparen door deze berekeningen zo dicht mogelijk bij het geheugen uit te voeren, met een lagere precisie. Daarom stelde de onderzoeksgroep van Verkest een nieuwe aanpak voor, die de traditionele computerarchitectuur volledig op de schop gooit: de berekeningen worden rechtstreeks in het geheugen uitgevoerd, door middel van analoge technologie.
De analoge aanpak
Een analoog systeem integreren in een digitaal systeem? Op het eerste zicht lijkt dat een vreemde zet in een wereld waarin alles gedigitaliseerd wordt. Analoge technieken, die gebruik maken van continue signalen in plaats van nulletjes en eentjes, zijn intrinsiek minder nauwkeurig. Maar zoals gezegd is het uitvoeren van elke bewerking met hoge precisie geen vereiste om tot een nauwkeurig eindresultaat te komen. Bovendien kom je met deze analoge aanpak sneller en met minder energieverbruik tot hetzelfde resultaat.
Hoe zit dat? Door gebruik te maken van de wetten van de elektriciteitsleer kunnen de bewerkingen van een matrix-vectorvermenigvuldiging in één keer worden uitgevoerd, in plaats van de ene na de andere. Als aan de invoerwaarden een voltage wordt toegekend en aan de aangeleerde parameters een conductantie, dan komt elke vermenigvuldiging overeen met een stroom (wet van Ohm). Die kan je optellen (stroomwet van Kirchoff), zodat de waarde van de stroom je het resultaat van de matrix-vectorvermenigvuldiging oplevert. Zo kan je de berekening rechtstreeks uitvoeren zonder dat je telkens opnieuw de parameters moet ophalen.

Om aan te tonen dat ook in de praktijk effectief werkt, werd de nieuwe architectuur geïntegreerd in een chip. De Analoge Inferentie Accelerator (AnIA), zoals de nieuwe chip genoemd wordt, haalt 2.900 TOPS/W, of 2.900 biljoen bewerkingen per Joule. “Dit is een referentie-implementatie, waarmee we willen aantonen dat het mogelijk is om analoge berekeningen in het geheugen uit te voeren”, zegt Verkest. “We kunnen dit op een compacte manier implementeren en de energie-efficiëntie ervan is nu al tien tot honderd keer beter dan die van digitale chips”.
Het ultieme doel is om uiteindelijk te evolueren naar 10.000 TOPS/W (10.000 biljoen bewerkingen per Joule). De concrete weg daar naartoe wordt beschreven in een recente paper, waarin een blauwdruk voor de ontwikkeling van zulke extreem energiezuinige en compacte chips wordt voorgesteld. Op die manier zullen draadloze sensoren autonoom patronen kunnen herkennen op de data die ze zelf verzameld hebben. Een heen-en-weertje naar een datacenter is dan niet langer nodig.



