
Streamingsdiensten en websites gebruiken een matrix om de individuele kijker de beste content aan te raden.
Data is de nieuwe olie, en data scientists zijn de mijnwerkers van dienst. Jobsites staan vol met advertenties van bedrijven die op zoek zijn naar de geknipte persoon om waarde uit hun data te halen. Veel van de commerciële, op data gebaseerde diensten maken ons leven makkelijker. Denk maar aan de suggesties die Netflix jou geeft wanneer je een avondje voor de tv wil ontspannen.
Dat Netflix voor dat suggestiemodel veel over heeft, is al lang duidelijk. Van 2006 tot 2009 sponsorde het bedrijf de Netflix Prize. De wedstrijd, met 1 miljoen dollar als hoofdprijs, had als doel een nieuw aanbevelingssysteem vinden. Daarvoor stelde Netflix zijn dataset van meer dan 100 miljoen gebruikersscores van films open, zodat de deelnemers hun systeem daarop konden enten. Op 21 september 2009 viel een winnaar uit de bus. Het team dat zichzelf Bellkor’s Pragmatic Chaos noemde, had een knap staaltje teamwerk geleverd, én wiskunde.
Ook muziek, producten bij online webshops en socialmediacontent worden ons op deze manier voorgeschoteld.
Een aanbevelingssysteem filtert uit een hele grote database die items die een gebruiker zouden kunnen interesseren. Deze systemen worden niet alleen gebruikt om films aan te bevelen, zoals bij Netflix of YouTube. Ook muziek, producten bij online webshops en socialmediacontent worden ons op deze manier voorgeschoteld. De Vlaamse MIT-professor Pattie Maes, die haar doctoraat in artificiële intelligentie behaalde aan de VUB, legde onder andere de basis voor zulke systemen.
Aanbevelingssystemen die gebaseerd zijn op zogenoemde collaborative filtering gebruiken een matrix of tabel met rijen en kolommen. In de kolommen komen alle producten – films bijvoorbeeld – en in de rijen komen de scores of likes van de gebruikers. Omdat niet elk product een score heeft, heeft zo’n matrix doorgaans redelijk wat lege plaatsen.
Datawetenschappers gaan met die matrix aan de slag. Binnen de grote groep gebruikers zoeken ze naar deelgroepen met een vergelijkbare smaak. (Ze houden daarbij geen rekening met factoren als leeftijd of het type film.) Ze kunnen op veel manieren omgaan met wat ‘vergelijkbaar’ betekent en daar op verschillende wijzes productsuggesties uit afleiden. Hoe dan ook komt er altijd wiskunde aan te pas.
Een mogelijkheid om gebruikers met een vergelijkbare smaak te vinden, bestaat erin om meetkundig te werk te gaan. Hierbij zetten data scientists de scores van de producten tegenover elkaar uit. De matrix en grafiek hiernaast, met twee producten en vier gebruikers, kunnen als voorbeeld dienen. De scores van gebruiker C leunen dicht aan bij B. Maar lijkt gebruiker B vervolgens meer op A of op D? In afstand liggen zijn scores dichter bij die van gebruiker D, maar is afstand wel een goede maat voor vergelijking? Zowel A als B vinden het tweede product tweemaal zo goed als het eerste, terwijl D ze allebei even goed vindt. Misschien geeft A wel streng punten en is D er veel vrijgeviger mee?
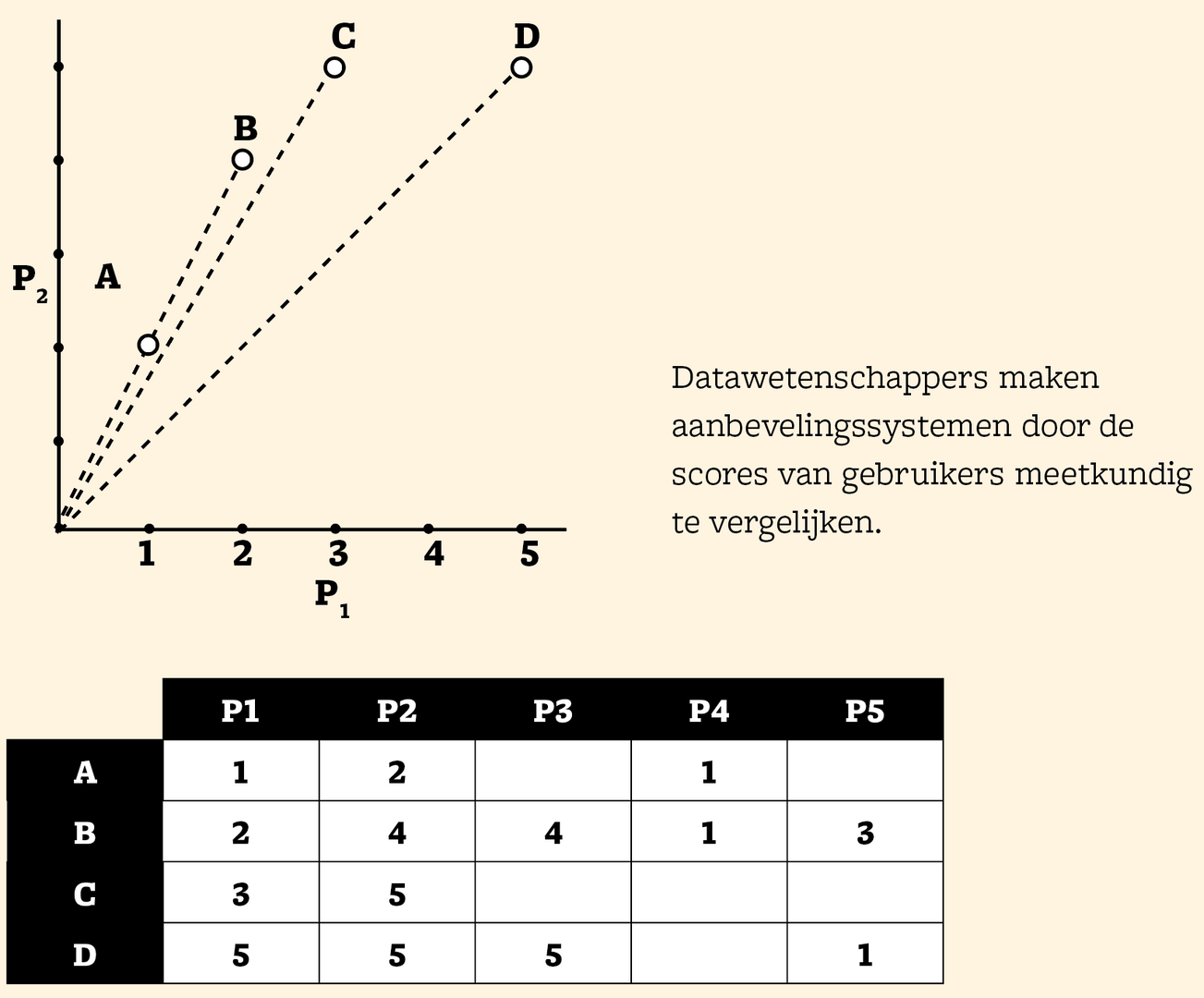
Het lijkt erop dat we gebruikers met een soortgelijke smaak kunnen vinden door te kijken naar de hoek tussen de stippellijnen op de grafiek. A en B liggen letterlijk en figuurlijk op dezelfde lijn. C wijkt daar niet ver van af. Wellicht is het een goed idee om de scores van A en B te extrapoleren naar producten die C nog niet kent. Dat kan je doen door te normaliseren en een gemiddelde te nemen van de scores. Daarvoor hou je rekening met een wegingsfactor, die afhangt van hoe vergelijkbaar de gebruikers zijn. Recente methodes maken eerder gebruik van lineaire-algebratechnieken. De formule van Bellkor’s Pragmatic Chaos is op die laatste gebaseerd.
Interesse om ook aan de slag te gaan als datawetenschapper? Bedrijven zoeken doorgaans een teamplayer met uitstekende communicatievaardigheden, die bovendien een expert is in wiskunde, statistiek en machine learning. En het liefst heeft hij of zij ervaring in exotisch klinkende softwarepakketten, zoals Scikit-learn, Pandas, Numpy, Spark, Hadoop, Keras en Tensorflow. Die pakketten zijn binnen tien jaar wellicht hopeloos gedateerd. Maar met kennis van de wiskunde ben je gewapend voor de datatoekomst.



