Hoe onderscheid je echte tweets van fake berichten van trollenlegers? Met twee algoritmes gebaseerd op een frisse set parameters, zo blijkt.
Naarmate de Amerikaanse presidentsverkiezingen naderen, zal het vaker dan ooit het nieuws halen: de geopolitieke strijd wordt niet meer gevoerd met conventionele legers en nucleaire arsenalen, maar met trollenlegers en digitale wapens. Eerder deze week waarschuwde William Evanina, directeur van de Amerikaanse digitale contraspionagedienst NCSC, bijvoorbeeld voor zowel Russische inmenging (pro-Trump), als Chinese (pro-Biden) én Iraanse (pro-algemene chaos in de VS).
Hoe stop je die trollenlegers zonder de vrijheid van meningsuiting in het gedrang te brengen? Door hun tweets te identificeren. Alleen is dat niet zo eenvoudig. Zelfs niet met algoritmes op basis van tijdstip, hashtag en geografische locatie. Specialist toegepaste taalkunde Sergei Monakhov pakte het daarom anders aan, met een onderzoek aan de Friedrich-Schiller-Universität (Jena). Research die, verzekert de universiteit, ‘niet extern gefinancierd werd en zonder belangenconflicten’. Lees: niet gemanipuleerd door een betrokken partij met het oog op een door haar gewenste uitkomst.
Monakhov deed een vergelijkend onderzoek naar een aantal echte tweets van Amerikaanse Congresleden versus een aantal fake tweets van Russische trollen. Hij gooide er een sociolinguïstisch net over, vanuit een tweeledig basisgegeven: trollen verspreiden slechts een beperkt aantal boodschappen, maar ze doen dat wel op een enorme schaal. Daarbij is toch voldoende diversiteit in taal en thema’s nodig. Anders valt een aparte tweet meteen door de mand als één van pakweg duizenden (nagenoeg) identieke tweets van een en dezelfde afzender op (nagenoeg) hetzelfde moment.
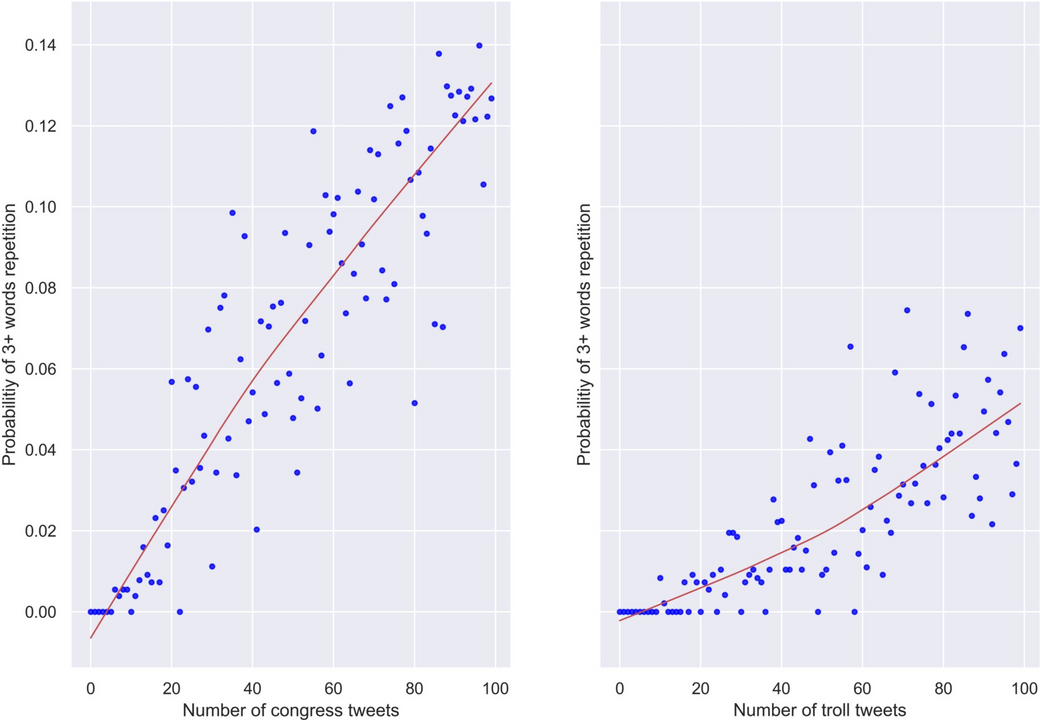
En dat is hun achilleshiel, stelde Monakhov vast. Binnen de grenzen van een boodschap die zowel kort als identiek moet zijn, kun je niet eindeloos variëren met taal. Het leidt al snel tot kunstgrepen. En die – het woord zegt het al – hebben iets kunstmatigs. Dat komt volgens Monakhov tot uiting in een concreet alarmsignaal: ‘Een anomalie in de verdeling van herhaalde woorden en woordparen. In een seriële tweet van een trol is die verdeling aanwijsbaar anders – gekunsteld, dus – dan in een individuele tweet van een individuele twitteraar.
‘Door dit te kwantificeren kwamen we tot twee algoritmes. Aan vijftig tweets hebben ze genoeg om een trol te ontmaskeren.’
Monakhov deed zelf de lakmoesproef met ’s werelds bekendste twitteraar: ‘Onze algoritmes zagen meteen het verschil tussen troltweets en echte van Donald Trump.’ Klinkt mooi, maar op de vraag of ze ook toepasbaar zijn op tweets van minder bekende tot heel gewone twitteraars komt hij niet verder dan een bekend cliché: ‘Dat moet verder onderzoek uitwijzen.’



